
2025 年 1 月 20 日开云·kaiyun体育,DeepSeek 谨慎发布 DeepSeek-R1 模子,并同步开源模子权重。
DeepSeek-R 大模子,资本价钱便宜,在许多第三方测试中,该模子的发扬也优于 OpenAI 的最新模子 o1,让硅谷恐慌,甚而激发了 Meta 里面的张惶,工程师们运转连夜尝试复制 DeepSeek 的后果。
DeepSeek 的邃密变现诱惑好多用户,以至于处事器几度被挤宕机。
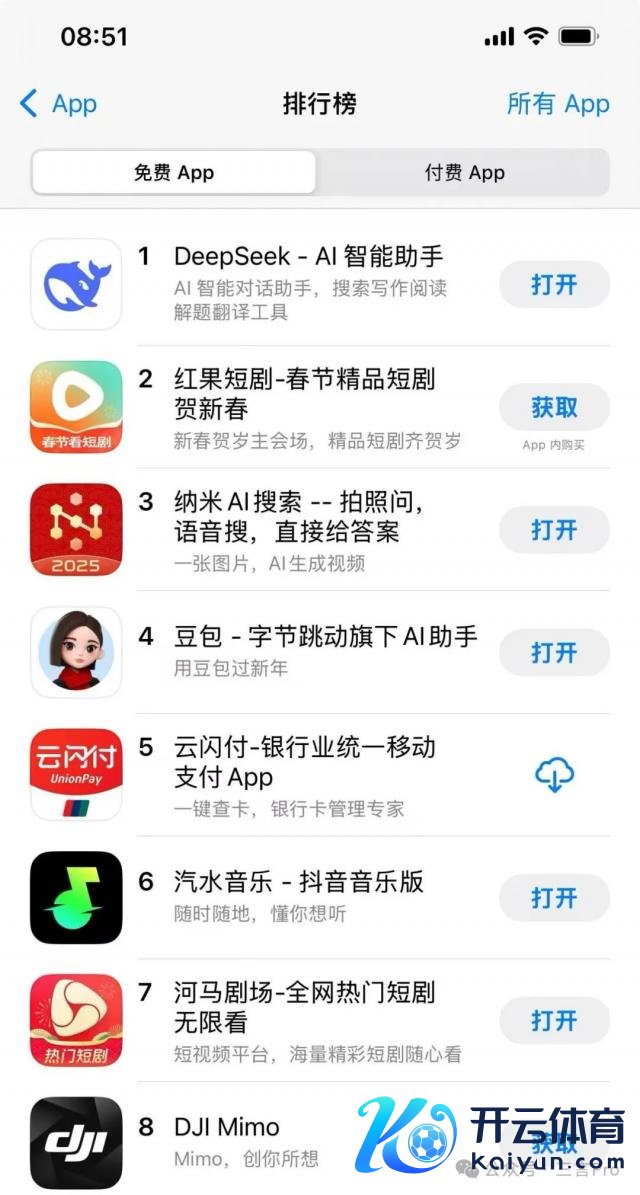
本日,DeepSeek 更是登顶苹果中国地区和好意思国地区期骗商店免费 App 下载名次榜,并在好意思区下载榜上突出了 ChatGPT。

微软 CEO、谷歌前 CEO 等大佬高度评价 DeepSeek
不少大佬都对 DeepSeek 评价颇高。
微软首席实行官萨蒂亚 · 纳德拉(Satya Nadella)辞寰宇经济论坛上谈到 DeepSeek 时表示:" DeepSeek 的新模子令东谈主印象真切,他们不仅有用地构建了一个开源模子,概况在推理计算时高效运行,而且在计算效用方面发扬出色。咱们必须极度极度谨慎地对待中国的 AI 越过。"
在最近的 ABC 节目中,谷歌前 CEO 埃里克 · 施密特(Eric Emerson Schmidt)篡改了好意思国在 AI 方面保握了两到三年最初上风的见解。他表示以前 6 个月,中国以一种人命交关的方式奋发有为,其中一个神气就包括 DeepSeek。
AI 科技初创公司 Scale AI 创举东谈主亚历山大 · 王(Alexandr Wang)也公开表示,中国东谈主工智能公司 DeepSeek 的 AI 大模子性能大致与好意思国最好的模子极度。
Benchmark 普通合资东谈主 Chetan Puttagunta 在最近的采访中表示,以前两周里东谈主工智能团队真的晴朗了眼界,用更少的资金创造了更多的可能性。以前要数亿好意思元才能作念到前哨,DeepSeek 让咱们看见用更少的资金就不错作念到这一切。
有名投资公司 A16z 的创举东谈主马克 · 安德森 1 月 24 日发文称,Deepseek-R1 是他见过的最令东谈主惊叹、最令东谈主印象真切的恣虐之一,而且如故开源的,它是给寰宇的一份礼物。
游戏科学创举东谈主、《黑悟空》制作主谈主冯骥发微博盛赞 DeepSeek 新推出的 DeepSeek-R1 模子。他表示我方使用 R1 仅 5 天,但仍是以为 DeepSeek "可能是个国运级别的科技后果"。
金沙江创投朱啸虎称 DeepSeek 是技巧欲望想法者的告捷。
外媒更是集体刷屏。英国《金融时报》1 月 25 日报谈称,中国袖珍 AI 初创公司 DeepSeek 恐慌硅谷。
Business Insider 报谈称,DeepSeek-R1 模子承袭洞开精神,完全开源,为好意思国 AI 玩家带来了艰难。
CNBC 40 分钟专题报谈
探讨 DeepSeek 对好意思国 AI 主导地位的冲击
1 月 24 日,好意思国媒体 CNBC 推出了长达 40 分钟的节目,邀请了好意思国 AI 初创公司 Perplexity 首席实行官 Aravind Srinivas 来分析为何 DeepSeek 会激发东谈主们对好意思国在 AI 界限的全球最初地位是否正在减轻的担忧。

"需求是发明之母",Aravind Srinivas 谈起 DeepSeek,"因为他们必须想办法绕过截止,最终内容上打造出了效用更高的东西。"
在对话中,Aravind Srinivas 不仅分析了 DeepSeek 对好意思国 AI 的影响,对 DeepSeek 的立异赐与了较高的评价,莫得一味搞对立,如故比较中肯的。
以下是对话原文(不影响容许的情况下翻译略有批改):
主握东谈主:请刻画中好意思之间的 AI 竞赛,以偏激中的猛烈相干。
Aravind Srinivas: 最先,中国在与好意思国的竞争中存在好多弱势。第一,他们无法得到咱们这里概况使用的整个硬件资源。他们基本上在使用比咱们低端的 GPU,险些像是上一代的 GPU。由于更大的模子时时更智能,这当然让他们处于弱势。
但另一方面,需求是发明之母。因为他们不得不寻找变通决策,最终他们内容上构建了更高效的惩办决策。这就像说:"嘿,你们必须构建一个顶级模子,但我不会给你们资源,你们得我方想办法。"除非数学上讲明注解这是不可能的,不然你总能尝试找到更高效的惩办决策。这可能会让他们比好意思国找到更高效的惩办决策。
固然,他们有开源模子,咱们也不错在这里收受雷同的东西。但他们培养的这种东谈主才将逐步成为他们的上风。咫尺,好意思国最初的开源模子是 Meta 的 Llama 系列,它极度出色,险些不错在你的电脑上运行。尽管它在发布时接近 GPT-4 的水平,但最接近质地的模子是弘远的 405B 参数模子,而不是你不错在电脑上运行的 70B 模子。因此,仍然莫得一个既小又便宜、快速且开源的模子概况与最苍劲的闭源模子相失色。
然后,这些中国团队推出了一个放肆的模子,API 价钱比 GPT-4 便宜 10 倍,甚而比 Claude 便宜 15 倍,速率极快,况且在某些基准测试中与 GPT-4 极度,甚而更好。他们只用了约莫 2048 个 H800 GPU,极度于 1500 到 2000 个 H100 GPU,这比 GPT-4 浅显考验的 GPU 数目少了 20 到 30 倍。他们整个只花了 500 万好意思元的计算机预算,就作念出了如斯惊东谈主的模子,况且免费公开了技巧论文。
主握东谈主:当你相识他们所作念的一切时,你的诧异是什么?
Aravind Srinivas: 我的诧异是,当我阅读他们的技巧论文时,他们淡薄了许多聪敏的惩办决策。最先,他们考验了一个搀杂人人模子(Mixture of Experts),这并拦截易考验。主要原因是东谈主们发现很难跟上 OpenAI 的措施,尤其是在 MoE 架构上,因为存在好多不规则的亏蚀峰值,数值不踏实,不时需要再行启动考验查抄点。他们淡薄了极度聪敏的惩办决策来均衡这极少,而不需要特等的手段。
他们还淡薄了 8 位浮点考验,至少在部分数值上。他们神秘地细则了哪些部分需要高精度,哪些部分不错低精度。据我所知,8 位浮点考验在好意思国并不常见,大多数考验仍然在 16 位进行,尽管有些东谈主正在探索这极少,但很难作念到正确。
由于需求是发明之母,他们莫得那么多内存和 GPU,因此他们找到了许多数值踏实的方法,使他们的考验概况告成进行。他们在论文中宣称,大部分考验是踏实的,这意味着他们不错随时再走运行这些考验,使用更多的数据或更好的数据。整个这个词考验只花了 60 天,这极度惊东谈主。
主握东谈主:你刚才说你很诧异。
Aravind Srinivas: 浅显的融会是中国东谈主擅长复制。淌若咱们罢手在好意思国发表酌量论文,罢手刻画咱们的基础法子架构细节,罢手开源,他们将无法赶上。但本质是,DeepSeek 3 中的一些细节极度出色,我甚而不会诧异 Meta 会模仿其中的一些内容,并将其期骗到 Llama 模子中。
这并不是说他们在复制,而是他们在立异。
主握东谈主:咱们并不完全知谈他们考验的数据是什么,尽管它是开源的,咱们知谈一些考验方式,但并不是一皆。有一种不雅点以为,它是基于 ChatGPT 的公开输出考验的,这意味着它只是复成品。但你说它突出了这极少,有信得过的立异。
Aravind Srinivas: 是的,他们考验了 14.8 万亿个 token。互联网上有太多 ChatGPT 生成的内容,淌若你当今去看任何 LinkedIn 帖子或 X 帖子,大多数褒贬都是由 AI 写的。甚而在 X 上,有 Grok 推文增强器,LinkedIn 上有 AI 增强器,Google Docs 和 Word 中也有 AI 器用来重写你的内容。淌若你在这些场合写了东西并复制粘贴到互联网上,当然会带有一些 ChatGPT 的考验脚迹。好多东谈主甚而懒得去掉"我是一个讲话模子"的部分。因此,这个界限很难戒指。
是以我不会因为某些教唆(比如"你是谁"或"你是哪个模子")而忽视他们的技巧确立。在我看来,这并不进攻。
主握东谈主:持久以来,咱们以为中国在 AI 界限逾期。这场竞赛对这场竞争有何影响?咱们能说中国正在奋发有为,如故仍是赶上了?
Aravind Srinivas: 淌若咱们说 Meta 正在赶上 OpenAI 或 Anthropic,那么雷同的说法也不错用于中国赶上好意思国。事实上,我看到中国有更多论文试图复制 OpenAI 的后果,甚而比好意思国还多。DeepSeek 概况使用的计算资源与好意思国的博士生极度。
主握东谈主:你会将 DeepSeek 整合到 Perplexity 中吗?
Aravind Srinivas: 咱们仍是运转使用它了。他们有 API,况且开源了,是以咱们也不错我方托管它。使用它内容上让咱们概况以更低的资本作念好多事情。
但我在想的是,他们内容上概况考验出如斯出色的模子,这对好意思国公司来说不再有借口不去尝试雷同的事情。
主握东谈主:你听到好多生成式 AI 界限的意见首级,无论是酌量如故创业方面,比如 Elon Musk 等东谈主,都说中国无法赶上,因为赌注太大。谁主导了 AI,谁就将主导经济,主导寰宇。你对中国讲明注解我方概况作念到的事神志到担忧吗?
Aravind Srinivas: 最先,我不细则 Elon 是否说过中国能赶上,我只知谈他提到了中国的挟制。Sam Altman 也说过雷同的话,咱们不可让中国赢。我的不雅点是,无论你作念什么来拦截他们赶上,最终他们如故赶上了。需求是发明之母。更危急的是,他们领有最好的开源模子,而整个好意思国建立者都在基于此构建。那样的话,他们将领有用户心智份额和生态系统。
淌若整个这个词好意思国 AI 生态系统都依赖于中国的开源模子,那将长短常危急的。历史上,一朝开源软件赶上或突出了闭源软件,整个建立者都会迁徙到开源。当 Llama 被构建并无为使用时,东谈主们曾质疑是否应该信任扎克伯格,但当今的问题是,咱们是否应该信任中国?
Aravind Srinivas: 从某种真谛上说,这并不进攻,因为你仍然不错完全戒指它,你不错在我方的计算机上运行它,你是模子的主东谈主。但对于咱们我方的技巧东谈主才来说,依赖别东谈主的软件并不是一个好情状,即使它是开源的。开源也可能有一天不再开源,许可证可能会篡改。因此,进攻的是咱们好意思国我方有东谈主才在构建这些技巧,这等于为什么 Meta 如斯进攻。
我以为 Meta 仍然会构建出比 DeepSeek 3 更好的模子,并将其开源。咱们不应该把整个的元气心灵都放在拦截他们、拦截他们上,而是应该努力突出他们,赢得竞争。这等于好意思国的方式,作念得更好。
咱们听到越来越多对于这些中国公司的音问,他们以更高效、更低资本的方式建立雷同的技巧。这照实让东谈主感到压力。
Aravind Srinivas: 是的,淌若你筹集了 100 亿好意思元,并决定将 80% 的资金用于计算机集群,那么你很难像那些只消 500 万好意思元预算的东谈主一样,找到雷同高效的惩办决策。这并不是说插足更多资金的东谈主莫得死力,他们只是试图尽快完成。
当咱们说开源时,有好多不同的版块。有些东谈主品评 Meta 莫得公开整个内容,甚而 DeepSeek 自己也并不完全透明。你不错说开源的极限是概况完全复制他们的考验历程,但有几许东谈主真的有资源作念到这极少呢?比较之下,他们在技巧敷陈等共享的细节仍是比许多其他公司多得多。
主握东谈主:当你预料 DeepSeek 作念这件事的资本不到 600 万好意思元时,再想想 OpenAI 建立 GPT 模子破耗了几许。这对闭源模子的生态系统轨迹、发展势头意味着什么?对 OpenAI 又意味着什么?
Aravind Srinivas: 很赫然,咱们将领有一个开源版块,甚而比闭源版块更好、更便宜。OpenAI 可能不会照顾这是否由他们制作,因为他们仍是转向了一个新的范式,称为 o1 系列模子。OpenAI 的 Ilya Sutskever 曾说过,预考验仍是碰到了瓶颈。这并不料味着推广仍是遣散,而是咱们在不同的维度上进行推广,比如模子想考的时候、强化学习等。
OpenAI 当今更专注于让模子在碰到新教唆时进行推理、收罗数据并与寰宇互动,使用多样器用。我以为这是改日的标的,而不单是是更大更好的模子。
Aravind Srinivas: 我以为 DeepSeek 也会将堤防力转向推理,这等于为什么我对他们下一步的后果感到激昂。
Aravind Srinivas: 那么,OpenAI 的下一步是什么?我以为咫尺还莫得东谈主概况构建出雷同 o1 的系统。尽管有东谈主质疑 o1 是否真的值得,但在某些教唆下,它的发扬照实更好。至少他们在 O3 中展示的遣散表露,它在竞争性编程中的发扬险些达到了 AI 软件工程师的水平。
主握东谈主:这是否只是时候问题,互联网上充满了推理数据,DeepSeek 也能作念到?
Aravind Srinivas: 有可能,但莫得东谈主知谈。在它遣散之前,不细则性仍然存在。
主握东谈主:到本年年底,推理界限是否会有多个玩家?
Aravind Srinivas:我皆备以为是这样。
主握东谈主:咱们是否正在看到大型讲话模子的营业化?
Aravind Srinivas: 我以为咱们会看到雷同的轨迹,就像预考验和后考验系统逐步营业化一样。本年会有更多的营业化,推理模子也会经历雷同的轨迹。最初可能只消一两个玩家知谈若何作念到,但跟着时候的推移,更多的玩家会加入。谁知谈呢,OpenAI 可能会在推理界限取得新的恣虐。
当今推理是他们的重心,但技巧越过会禁止发生。跟着时候推移,今天的模子所具备的推理才协调多模态才调,将会以更低资本的开源模子姿首出现。唯独不细则的是,像概况在推理时进行想考的模子,是否概况便宜到足以在咱们的手机上运行。
主握东谈主:嗅觉跟着 DeepSeek 所讲明注解的才调,整个这个词 AI 界限的面貌仍是发生了变化。你能称之为中国的 ChatGPT 时刻吗?
Aravind Srinivas: 有可能。我以为这无疑给了他们好多信心,标明他们并莫得逾期。无论你若何截止他们的计算资源,他们总能找到变通决策。我深信团队对他们的后果感到极度激昂。
主握东谈主:这若何篡改投阅历局?那些每年破耗数百亿好意思元在计算资源上的超大范畴公司,以及 OpenAI 和 Anthropic 等筹集数十亿好意思元用于 GPU 的公司,DeepSeek 告诉咱们,你并不一定需要那么多资源。
Aravind Srinivas: 我以为很赫然,他们会愈加专注于推理,因为他们认识,无论他们以前两年在构建什么,当今都变得极度便宜,以至于持续插足广宽资金不再合理。他们是否需要雷同多的高端 GPU,如故不错使用 DeepSeek 那样的低端 GPU 进行推理?这很难说,除非被讲明注解不行。
但在快速前进的精神下,你可能会但愿使用高端芯片,以便比竞争敌手更快。最优秀的东谈主才仍然但愿加入那些最先行者逐恣虐的团队。总有一些荣耀属于信得过的前驱者,而不是快速奴婢者。
主握东谈主:这有点像 Sam Altman 的推文,示意 DeepSeek 只是复制了别东谈主的后果。
Aravind Srinivas: 但你也不错说,在这个界限,每个东谈主都在复制别东谈主。你不错说 Google 最先淡薄了 Transformer,OpenAI 只是复制了它。Google 构建了第一个大型讲话模子,但莫得优先发展它,而 OpenAI 则将其算作优先事项。是以你不错说这些,但在好多方面,这并不进攻。
主握东谈主:我牢记我问过你,为什么你不想构建模子。你说那是一场极其不菲的竞赛,而当今一年后,你看起来极度聪敏,莫得卷入这场竞争。你当今在寰球想要看到的界限——生成式 AI 的杀手级期骗——占据了最初地位。请谈谈这个决定,以及你若何看待 Perplexity 的改日。
Aravind Srinivas: 一年前,咱们甚而莫得像 GPT-3.5 这样的模子。咱们有 GPT-4,但莫得东谈主概况赶上它。我的嗅觉是,淌若那些领有更多资源和更多才华的东谈主都无法赶上,那么参与这场游戏长短常困难的。是以咱们决定玩一个不同的游戏。无论若何,东谈主们都想使用这些模子,而一个标的是淡薄问题并得到准确的谜底,附带开头和及时信息。
在模子除外,确保居品可靠运行、推广使用范畴、构建自界说 UI 等方面还有好多使命要作念。咱们会专注于这些,并受益于模子变得越来越好。事实上,GPT-3.5 让咱们的居品变得极度好。淌若你在 Perplexity 中聘任 GPT-3.5 算作模子,险些很难找到幻觉。这并不是说它不可能发生,但它大大减少了幻觉的发生率。
这意味着,发问、得到谜底、进行事实核查、酌量、经营任何信息的问题,险些整个的信息都在网上,这是一个弘远的解锁。这匡助咱们在以前一年顶用户量增长了十倍。咱们在用户方面取得了巨猛进展,好多大投资者都是咱们的粉丝,比如黄仁勋,他在最近的主题演讲中提到了咱们,他内容上是一个不时使用的用户。
主握东谈主:一年前,咱们甚而莫得辩论营业化,因为你们还很新,只想扩大范畴。但当今你们正在计议告白模式。
Aravind Srinivas: 是的,咱们正在尝试。我知谈这引起了一些争议,比如为什么咱们要作念告白,是否不错在有告白的情况下仍然提供的确的谜底。在我看来,咱们一直极度积极地想考这个问题。咱们说过,只消谜底永远准确、无偏见,况且不受告白预算的影响,你只会看到一些扶助问题。甚而这些扶助问题的谜底也不受告白影响。
告白商也但愿你知谈他们的品牌,并了解他们品牌的最好部分,就像你在先容我方时但愿别东谈主看到你最好的一面一样。但你仍然无须点击扶助问题,你不错忽略它。咱们咫尺只按 CPM 收费,是以还莫得激励你去点击。
计议到整个这些,咱们内容上是在尝试持久作念对的事情,而不是像 Google 那样将就你点击纠合。
主握东谈主:我牢记一年前东谈主们辩论模子商品化时,你以为这是有争议的,但当今这不再有争议了。这种情况正在发生,你关注这极少是颖慧的。
Aravind Srinivas: 趁便说一句,咱们从模子商品化中获益匪浅,但咱们还需要为付用度户提供一些特等的价值,比如一个更高档的酌量代理,概况进行多步推理,进行 15 分钟的搜索,并给出分析类型的谜底。整个这些都将保留在居品中,不会有任何变化。
但免用度户每天淡薄的 1 万亿个问题需要快速陈诉,这些必须保握免费。这意味着咱们需要找到一种方法,使这些免费流量也概况货币化。
主握东谈主:你并不是试图篡改用户俗例,但你正在试图教告白商新的俗例。他们不可像在 Google 的蓝色纠合搜索中那样得到一切。到咫尺为止,告白商的反馈若何?他们雅瞻念给与这些衡量吗?
Aravind Srinivas: 是的,这等于为什么他们在尝试与咱们合营。许多品牌都在与咱们合营测试。他们也很激昂,因为无论可爱与否,改日大多数东谈主都将通过 AI 发问,而不是传统的搜索引擎。每个东谈主都认识这极少,是以他们都但愿成为新平台、新用户体验的早期收受者,并从中学习,共同构建改日。
主握东谈主:我笑了,因为这无缺地回到了你今天一运转提到的不雅点:需求是发明之母。告白商们正在看到这个界限的变化,他们必须学会相宜。
Aravind Srinivas: 没错,这等于告白商们正在作念的事情,他们说这个界限正在变化,咱们必须学会相宜。
主握东谈主:好的,Aravind,我占用了你这样多时候,极度感谢你抽出时候。
Aravind Srinivas: 谢谢你开云·kaiyun体育。